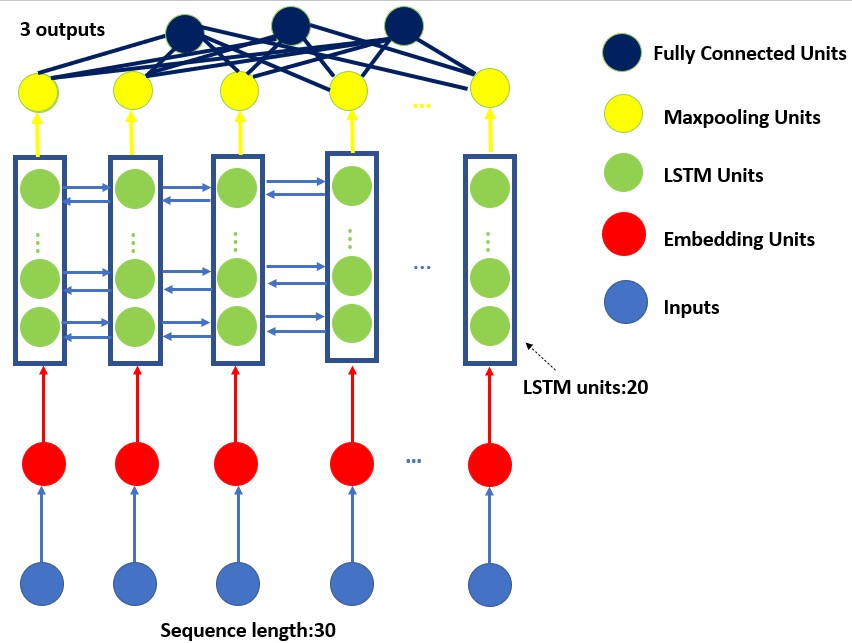
Deploying Scalable Machine Learning Models for Drug Discovery and LLM Fine-Tuning Using AWS Services
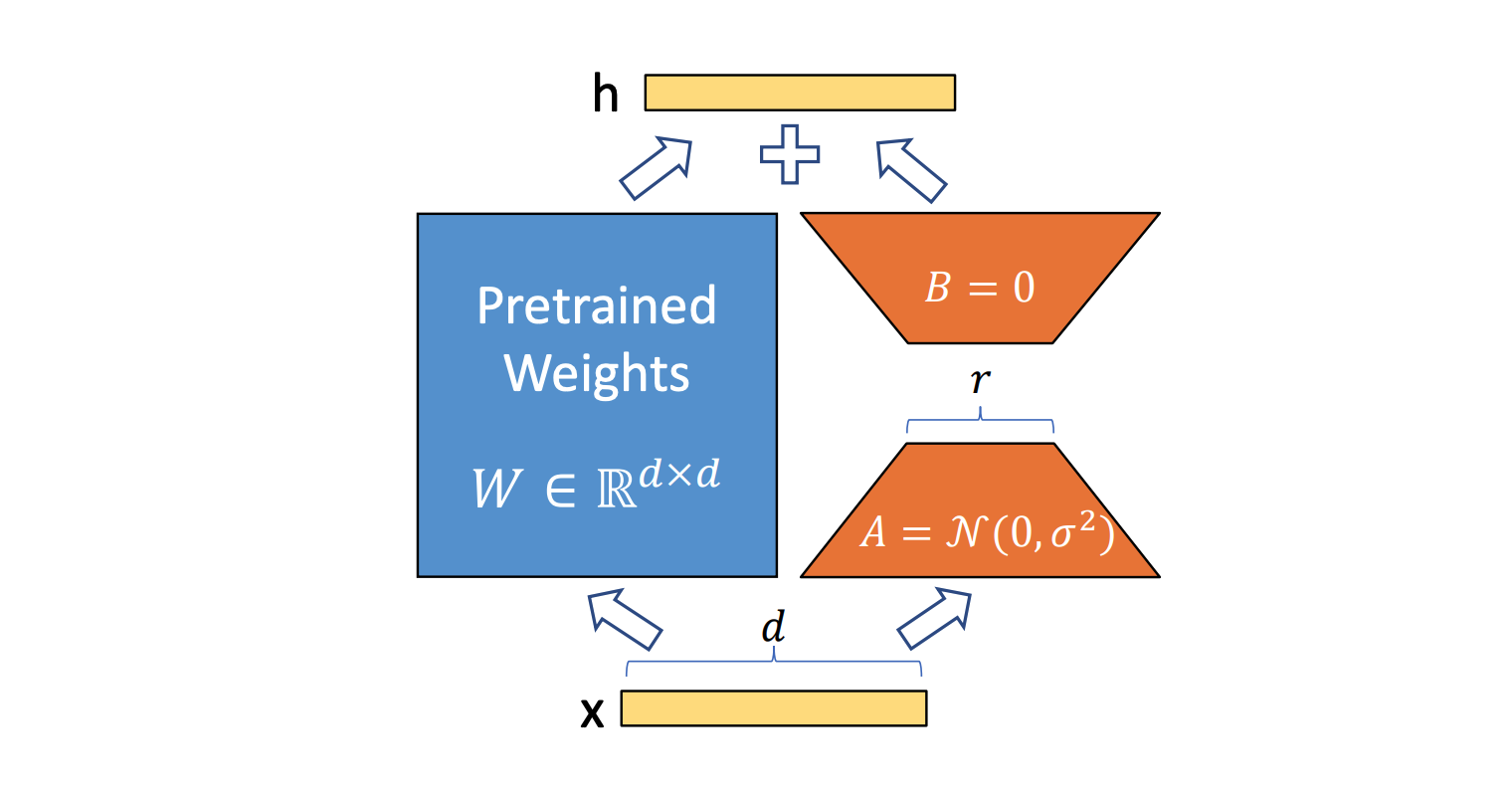
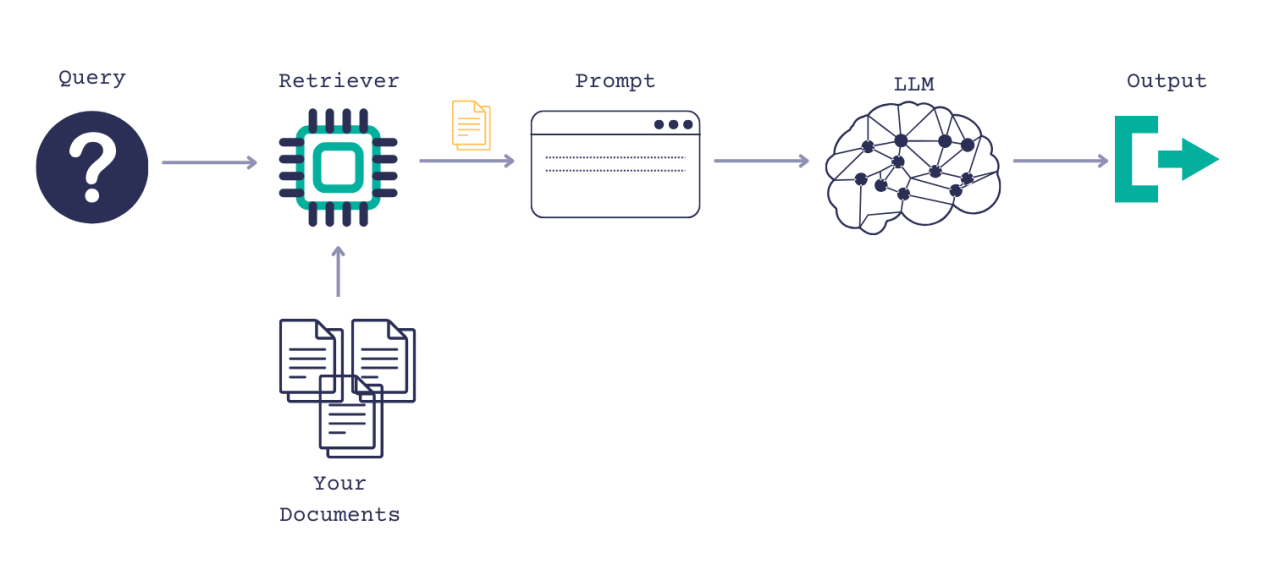
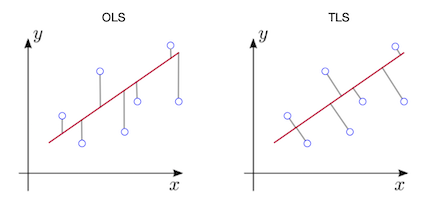
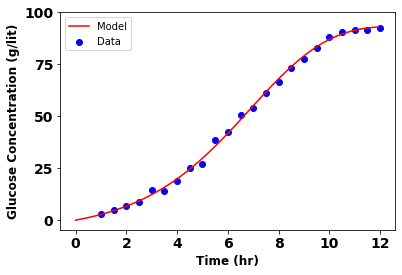
Using AWS services including AWS ECR, Lambda, and API Gateway, I deployed machine learning models that have been used for drug discovery associated with Dengue Fever. I also fine-tuned a small-sized LLM and deployed it on AWS using AWS Lambda. In this project, Docker-based Lambda functions were deployed, which is a serverless service that is ultimately great for scalable deployment of machine learning models. I created APIs associated with each of the models using three different approaches: i) using Flask, ii) using API Gateway, and iii) using SageMaker endpoints. The UI of these models was developed using Streamlit.[More]